文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
声明:作者翻译论文仅为学习,如有侵权请联系作者删除博文,谢谢!
翻译论文汇总:https://github.com/SnailTyan/deep-learning-papers-translation
MobileNetV2: Inverted Residuals and Linear Bottlenecks
摘要
在本文中,我们描述了一种新的移动架构MobileNetV2,该架构提高了移动模型在多个任务和多个基准数据集上以及在不同模型尺寸范围内的最佳性能。我们还描述了在我们称之为SSDLite的新框架中将这些移动模型应用于目标检测的有效方法。此外,我们还演示了如何通过DeepLabv3的简化形式,我们称之为Mobile DeepLabv3来构建移动语义分割模型。
MobileNetV2架构基于倒置的残差结构,其中快捷连接位于窄的瓶颈层之间。中间展开层使用轻量级的深度卷积作为非线性源来过滤特征。此外,我们发现为了保持表示能力,去除窄层中的非线性是非常重要的。我们证实了这可以提高性能并提供了产生此设计的直觉。
最后,我们的方法允许将输入/输出域与变换的表现力解耦,这为进一步分析提供了便利的框架。我们在ImageNet[1]分类,COCO目标检测[2],VOC图像分割[3]上评估了我们的性能。我们评估了在精度、通过乘加(MAdd)度量的操作次数,以及实际的延迟和参数的数量之间的权衡。
1. 引言
神经网络已经彻底改变了机器智能的许多领域,使具有挑战性的图像识别任务获得了超过常人的准确性。然而,提高准确性的驱动力往往需要付出代价:现代先进网络需要超出许多移动和嵌入式应用能力之外的高计算资源。
本文介绍了一种专为移动和资源受限环境量身定制的新型神经网络架构。我们的网络通过显著减少所需操作和内存的数量,同时保持相同的精度推进了移动定制计算机视觉模型的最新水平。
我们的主要贡献是一个新的层模块:具有线性瓶颈的倒置残差。该模块将输入的低维压缩表示首先扩展到高维并用轻量级深度卷积进行过滤。随后用线性卷积将特征投影回低维表示。官方实现可作为[4]中TensorFlow-Slim模型库的一部分。
这个模块可以使用任何现代框架中的标准操作来高效地实现,并允许我们的模型使用标准基线沿多个性能点击败最先进的技术。此外,这种卷积模块特别适用于移动设计,因为它可以通过从不完全实现大型中间张量来显著减少推断过程中所需的内存占用。这减少了许多嵌入式硬件设计中对主存储器访问的需求,这些设计提供了少量高速软件控制缓存。
2. 相关工作
调整深层神经架构以在精确性和性能之间达到最佳平衡已成为过去几年研究活跃的一个领域。由许多团队进行的手动架构搜索和训练算法的改进,已经比早期的设计(如AlexNet[5],VGGNet [6],GoogLeNet[7]和ResNet[8])有了显著的改进。最近在算法架构探索方面取得了很多进展,包括超参数优化[9,10,11]、各种网络修剪方法[12,13,14,15,16,17]和连接学习[18,19]。 也有大量的工作致力于改变内部卷积块的连接结构如ShuffleNet[20]或引入稀疏性[21]和其他[22]。
最近,[23,24,25,26]开辟了了一个新的方向,将遗传算法和强化学习等优化方法带入架构搜索。然而,一个缺点是最终所得到的网络非常复杂。在本文中,我们追求的目标是发展了解神经网络如何运行的更好直觉,并使用它来指导最简单可能的网络设计。我们的方法应该被视为[23]中描述的方法和相关工作的补充。在这种情况下,我们的方法与[20,22]所采用的方法类似,并且可以进一步提高性能,同时可以一睹其内部的运行。我们的网络设计基于MobileNetV1[27]。它保留了其简单性,并且不需要任何特殊的运算符,同时显著提高了它的准确性,为移动应用实现了在多种图像分类和检测任务上的最新技术。
3. 准备,讨论和直觉
3.1. 深度可分卷积
深度可分卷积是许多高效神经网络架构的关键组成部分[27,28,20],我们在目前的工作中也使用它们。其基本思想是用分解版本替换完整的卷积运算符,将卷积拆分为两个单独的层。第一层称为深度卷积,它通过对每个输入通道应用单个卷积滤波器来执行轻量级滤波。第二层是1×1卷积,称为逐点卷积,它负责通过计算输入通道的线性组合来构建新特征。
标准卷积使用$K\in \mathbf{R}^{k\times k \times d_i \times d_j}$维的输入张量$L_i$,并对其应用卷积核$K\in \mathbf{R}^{k\times k \times d_i \times d_j}$来产生$h_i\times w_i\times d_j$维的输出张量$L_j$。标准卷积层的计算代价为$h_i \cdot w_i \cdot d_i \cdot d_j \cdot k \cdot k$。
深度可分卷积是标准卷积层的直接替换。经验上,它们几乎与常规卷积一样工作,但其成本为:$$\begin{equation}h_i \cdot w_i \cdot d_i (k^2 + d_j) \tag{1}\end{equation}$$它是深度方向和$1\times 1$逐点卷积的总和。深度可分卷积与传统卷积层相比有效地减少了几乎$k^2$倍的计算量。MobileNetV2使用$k=3$($3\times 3$的深度可分卷积),因此计算成本比标准卷积小$8$到$9$倍,但精度只有很小的降低[27]。
3.2. 线性瓶颈
考虑一个由$n$层$L_i$组成的深度神经网络,每层都有一个$h_i \times w_i \times d_i$维的激活张量。在本节中,我们将讨论这些激活张量的基本属性,我们将把它们看作$h_i \times
w_i$个具有$d_i$维的“pixels”。非正式地,对于输入的一组真实图像,我们说层激活的集合(对于任何层$L_i$)形成一个“感兴趣的流形”。长久以来,人们一直认为神经网络中的流形可以嵌入到低维子空间中。换句话说,当我们查看深层卷积层的所有单独的$d$通道像素时,在这些值中编码的信息实际上位于某个流形中,这反过来又可嵌入到低维子空间中。
乍一看,这样的实例可以通过简单地减少层的维度来捕获和利用,从而降低操作空间的维度。这已经被MobileNetV1[27]成功利用,通过宽度乘数参数在计算量和精度之间进行有效折衷,并且已经被合并到其他网络的高效模型设计中[20]。遵循这种直觉,宽度乘数方法允许降低激活空间的维度,直到感兴趣的流形横跨整个空间为止。然而,当我们回想到深度卷积神经网络实际上具有非线性的每个坐标变换(例如ReLU)时,这种直觉就会失败。 例如,在1维空间中的一行应用ReLU会产生一个ray,在$\mathbf {R}^n$空间中,它通常会产生一个具有$n$个连接的分段线性曲线。
很容易看出,如果层变换ReLU(Bx)的结果具有非零的体积$S$,映射到内部$S$的点通常通过输入的线性变换$B$获得,因此表明与全维度输出相对应的输入空间的一部分受限于线性变换。换句话说,深层网络只在输出域的非零体积部分具有线性分类器的能力。我们将在补充材料中进行更正式的说明。
另一方面,当ReLU破坏通道时,它不可避免地会丢失该通道的信息。但是,如果我们有很多通道,并且激活流形中有一个结构,信息可能仍然保留在其它通道中。在补充材料中,我们说明,如果输入流形可以嵌入到激活空间的显著较低维子空间中,则ReLU变换将保留该信息,同时将所需的复杂性引入到可表达的函数集中。
总而言之,我们已经强调了两个特性,这些特性表明需要的感兴趣流行应该位于较高维激活空间的低维子空间中:
1.如果感兴趣的流形在ReLU转换后保持非零体积,则其对应于线性转换。
2.只有当输入流形位于输入空间的低维子空间时,ReLU才能保留有关输入流形的完整信息。
这两个深刻见解为我们提供了优化现有神经架构的经验提示:假设感兴趣流形是低维的,我们可以通过将线性瓶颈层插入到卷积模块中来捕获这一点。实验证据表明,使用线性层是至关重要的,因为它可以防止非线性破坏太多的信息。在第6节中,我们通过经验证明,在瓶颈中使用非线性层确实会使性能降低几个百分点,进一步证实了我们的假设。我们注意到[29]报告了非线性得到帮助的类似报告,其中非线性已从传统残差块的输入中移除,并导致CIFAR数据集的性能得到了改善。
对于本文的其余部分,我们将利用瓶颈卷积。我们将把输入瓶颈的大小与内部大小之间的比例作为扩展比。
3.3. 倒置残差
瓶颈块与残差块类似,其中每个块包含一个输入,然后是几个瓶颈,然后是扩展[8]。然而,受直觉的启发,瓶颈实际上包含所有必要的信息,而扩展层只是伴随张量非线性变换的实现细节,我们直接在瓶颈之间使用快捷连接。图3提供了设计差异的示意图。插入快捷连接的动机与经典的残差连接类似:我们想要提高梯度在乘法层之间传播的能力。但是,倒置设计的内存效率要高得多(详见第5节),而且在我们的实验中效果稍好。
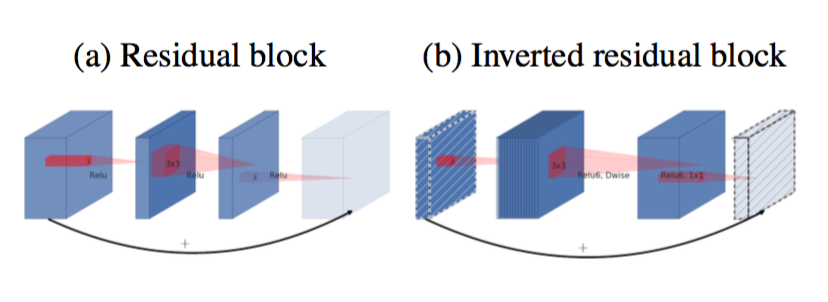
图3:残差块[8,30]和倒置残差之间的差异。对角阴影线层不使用非线性。我们用每个块的厚度来表明其相对数量的通道。注意经典残差是如何将通道数量较多的层连接起来的,而倒置残差则是连接瓶颈。最好通过颜色看。
瓶颈卷积的运行时间和参数计数基本实现结构如表1所示。对于大小为$h\times w$的块,扩展因子为$t$,内核大小为$k$,具有$d’$维输入通道和$d’’$维输出通道,所需的乘法加法总数为$h \cdot w \cdot d’ \cdot t(d’ + k^2 + d’’)$。与(1)相比,这个表达式有一个额外项,因为实际上我们有一个额外的1×1卷积,但是我们的网络性质使我们能够利用更小的输入和输出维度。在表3中,我们比较了MobileNetV1,MobileNetV2和ShuffleNet之间每种分辨率所需的尺寸。

表1:瓶颈残差块从$k$转换为$k’$个通道,步长为$s$,扩展系数为$t$。
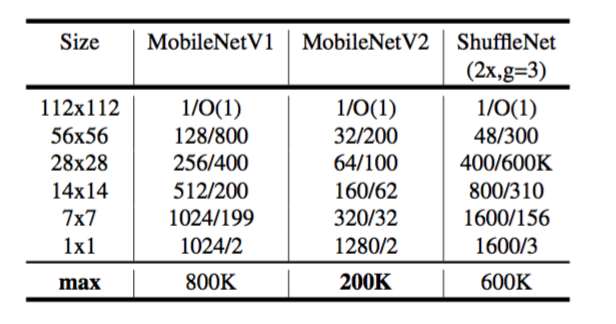
表3:不同架构中需要在每个空间分辨率上实现的最大通道数/内存(以Kb为单位)。我们假设激活使用16位浮点数。对于ShuffleNet,我们使用与MobileNetV1和MobileNetV2的性能相匹配的$2x,g = 3 $。对于MobileNetV2和ShuffleNet的第一层,我们可以采用第5节中描述的技巧来降低内存需求。尽管ShuffleNet在其它地方使用了瓶颈,但由于存在非瓶颈张量之间的快捷连接,因此非瓶颈张量仍然需要实现。
3.4. 信息流解释
我们架构的一个有趣特性是它在构建块(瓶颈层)的输入/输出域与层转换之间提供了自然分离——这是一种将输入转换为输出的非线性函数。前者可以看作是网络在每一层的容量,而后者则是表现力。与常规和可分离的传统卷积块相比,其中表现力和容量都缠结在一起并且是输出层深度的函数。
特别是在我们的实例中,当内层深度为0时,由于快捷连接,基础卷积是恒等函数。当扩展比率小于1时,这是一个经典的残差卷积块[8,30]。但是,就我们的目的而言,我们表明扩大比率大于1是最有用的。
这种解释使我们能够独立于其容量研究网络的表现力,并且我们认为需要进一步探索这种分离,以便更好地理解网络性质。
4. 模型架构
现在我们详细描述我们的架构。正如前一节所讨论的那样,基本构件块是一个瓶颈深度可分离的残差卷积。该模块的详细结构如表1所示。MobileNetV2的架构包含具有32个滤波器的初始全卷积层,接着是表2中描述的19个残差瓶颈层。我们使用ReLU6作为非线性,因为用于低精度计算时它的鲁棒性[27]。我们总是使用现代网络中的标准核尺寸3×3,并在训练期间利用丢弃和批归一化。
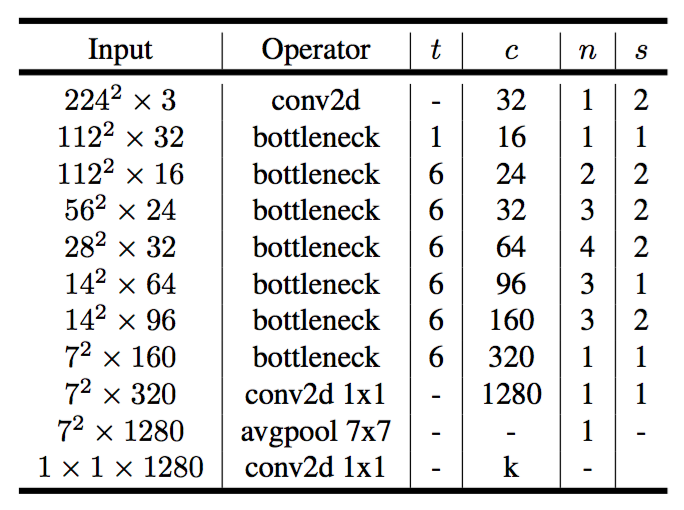
表2:MobileNetV2:每行描述一个或多个相同(模步长)层的序列,重复$n$次。同一序列中的所有图层具有相同数量的$c$个输出通道。每个序列的第一层有一个步长$s$,所有其他的都使用长$1$。所有空间卷积使用3×3的核。扩展系数$t$总是应用于输入尺寸,如表1所述。
除第一层外,我们在整个网络中使用恒定的扩展率。在我们的实验中,我们发现5到10之间的扩展速率导致几乎相同的性能曲线,较小的网络以较小的扩展速率更好,而较大的网络在较大扩展速率时具有稍微更好的性能。
对于我们所有的主要实验,我们使用扩展因子$6$来应用于输入张量的大小。例如,对于瓶颈层采用$64$通道的输入张量并产生具有$128$通道的张量,中间扩展层则具有$64·6 =384$个通道。
和[27]一样,我们通过使用输入图像分辨率和宽度倍数作为可调超参数来调整我们的架构以适应不同的性能点,可以根据所需的精度/性能权衡来调整。我们的主要网络(宽度乘数1,224×224)的计算成本为3亿次乘法,并使用了340万个参数。我们研究了性能权衡,输入分辨率从96到224,宽度乘数从0.35到1.4。网络计算成本范围从7次乘法增加到585M MAdds,而模型大小在1.7M个参数和6.9M个参数之间变化。
一个较小的实现差异,[27]是对于小于1的乘数,我们将宽度乘数应用于除最后一个卷积层以外的所有层。这可以提高更小模型的性能。
5. 实现说明
5.1. 内存有效推断
倒置的残差颈层允许特定地内存有效的实现,这对于移动应用非常重要。使用TensorFlow[31]或Caffe[32]等标准高效的推断实现,构建了一个有向无环计算超图$G$,由表示操作的边和代表中间计算张量的节点组成。预定计算是为了最小化需要存储在内存中的张量总数。在最一般的情况下,它会搜索所有合理的计算顺序$\Sigma (G)$,并选择最小化$$ M(G) = \min_{\pi\in \Sigma(G)} \max_{i \in 1..n} \left[\sum_{A \in R(i, \pi, G)} |A|\right] + \text{size}(\pi_i)$$。$$其中$R(i, \pi, G)$是连接到任何$\pi_{i}\dots \pi_{n}$节点的中间张量列表,$|A|$表示张量$A$的大小,$size(i)$是操作$i$期间内部存储所需的总内存量。
对于仅具有平凡并行结构(例如残差连接)的图,只有一个非平凡的可行计算顺序,因此可以简化计算图$G$推断所需的内存总量和界限:$$M(G) = \max_{op \in G} \left[\sum_{A \in \text{op}_{inp}} |A| + \sum_{B \in \text{op}_{out}} |B| + |op|\right] \tag {2}$$或者重申,内存量只是在所有操作中组合输入和输出的最大总大小。在下文中我们将展示如果我们将瓶颈残差块视为单一操作(并将内部卷积视为一次性张量),则总内存量将由瓶颈张量的大小决定,而不是瓶颈的内部张量的大小(更大)。
瓶颈残差块 图3b中所示的$\mathcal{F}(x)$可以表示为三个运算符的组合$\mathcal{F}(x) = [A \circ \mathcal{N} \circ B] x$,其中$A$是线性变换$A:\mathcal{R}^{s \times s \times k} \rightarrow \mathcal{R}^{s \times s \times n}$,$\mathcal{N}$是一个非线性的每个通道的转换:$\mathcal{N}: \mathcal{R}^{s \times s \times n} \rightarrow \mathcal{R}^{s’ \times s’ \times n}$,$B$是输出域的线性转换:$B: \mathcal{R}^{s’ \times s’ \times n} \rightarrow \mathcal{R}^{s’ \times s’ \times k’}$。
对于我们的网络$\mathcal{N} = ReLU6 \circ dwise \circ ReLU6$,但结果适用于任何的按通道转换。假设输入域的大小是$|x|$并且输出域的大小是$|y|$,那么计算$F(X)$所需的内存可以低至$|s^2 k| + |s’^2 k’| + O(\max(s^2, s’^2))$。
该算法基于以下事实:内部张量$\cal I$可以表示为$t$张量的连接,每个大小为$n/t$,则我们的函数可以表示为$$\mathcal{F}(x) = \sum_{i=1}^t (A_i \circ N \circ B_i)(x)$$通过累加和,我们只需要将一个大小为$n/t$的中间块始终保留在内存中。使用$n=t$,我们最终只需要保留中间表示的单个通道。使我们能够使用这一技巧的两个约束是(a)内部变换(包括非线性和深度)是每个通道的事实,以及(b)连续的非按通道运算符具有显著的输入输出大小比。对于大多数传统的神经网络,这种技巧不会产生显著的改善。
我们注意到,使用$t$路分割计算$F(X)$所需的乘加运算符的数目是独立于$t$的,但在现有实现中,我们发现由于增加的缓存未命中,用几个较小的矩阵乘法替换一个矩阵乘法会很损坏运行时的性能 。我们发现这种方法最有用,$t$是$2$和$5$之间的一个小常数。它显著降低了内存需求,但仍然可以利用深度学习框架提供的高度优化的矩阵乘法和卷积算子来获得的大部分效率。如果特殊的框架级优化可能导致进一步的运行时改进,这个方法还有待观察。
6. 实验
6.1. ImageNet分类
训练设置我们使用TensorFlow[31]训练我们的模型。我们使用标准的RMSPropOptimizer,将衰减和动量都设置为0.9。我们在每层之后使用批标准化,并将标准权重衰减设置为0.00004。遵循MobileNetV1 [27]的设置,我们使用初始学习率为0.045,学习率的衰减比率为每个迭代周期衰减0.98。我们使用16个GPU异步,批大小为96。
结果我们将我们的网络与MobileNetV1,ShuffleNet和NASNet-A模型进行了比较。表4列出了一些选定模型的统计数据,完整的性能图如图5所示。
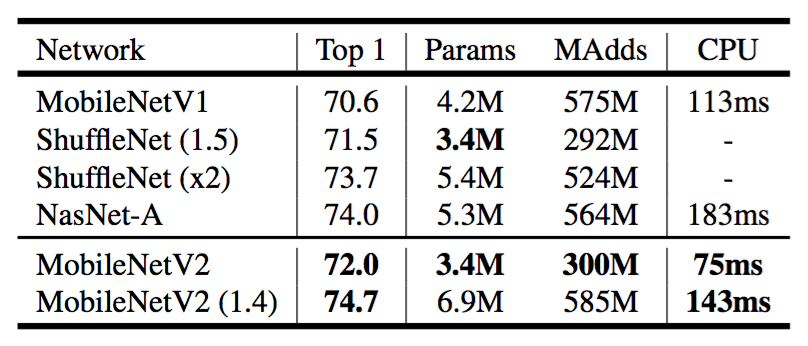
表4:比较不同网络在ImageNet上的性能。正如ops的常见做法一样,我们计算Multiply-Adds的总数。在最后一列中,我们报告了Google Pixel 1手机上的一个大型核心(使用TF-Lite)的运行时间,以毫秒(ms)为单位。我们不报告ShuffleNet的数字,因为高效的群组卷积和混排尚未支持。
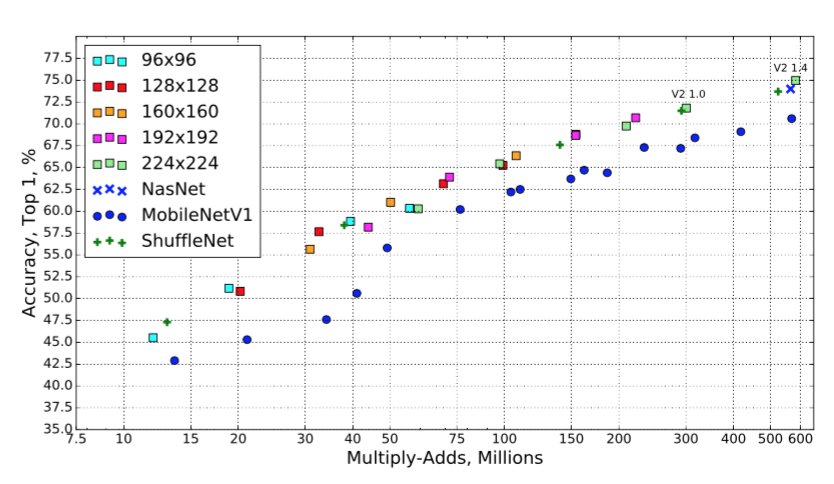
图5:MobileNetV2与MobileNetV1,ShuffleNet,NAS的性能曲线。对于我们的网络,我们对所有分辨率使用乘数0.35,0.5,0.75,1.0,对于分辨率为224,我们使用乘数1.4。
6.2. 目标检测
我们评估和比较了MobileNetV2和MobileNetV1的性能,MobileNetV1使用COCO数据集[2]上Single Shot Detector(SSD)[34]的修改版本作为目标检测的特征提取器[33]。我们还将YOLOv2[35]和原始SSD(以VGG-16[6]为基础网络)作为基准进行比较。由于我们专注于移动/实时模型,因此我们不会比较Faster-RCNN[36]和RFCN[37]等其它架构的性能。
SSDLite 在本文中,我们将介绍常规SSD的移动友好型变种。我们在SSD预测层中用可分离卷积(深度方向后接$1\times 1$投影)替换所有常规卷积。这种设计符合MobileNets的整体设计,并且在计算上效率更高。我们称之为修改版本的SSDLite。与常规SSD相比,SSDLite显著降低了参数计数和计算成本,如表5所示。
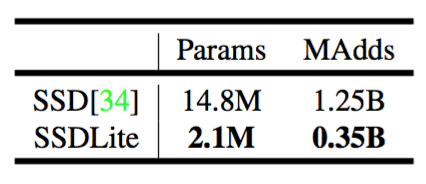
表5:使用MobileNetV2配置的SSD和SSDLite之间的大小和计算成本以及对80个类进行预测的比较。
对于MobileNetV1,我们按照[33]中的设置进行。对于MobileNetV2,SSDLite的第一层被附加到层15的扩展(输出步长为16)。SSDLite层的第二层和其余层连接在最后一层的顶部(输出步长为32)。此设置与MobileNetV1一致,因为所有层都附加到相同输出步长的特征图上。
MobileNet模型都经过了开源TensorFlow目标检测API的训练和评估[38]。 两个模型的输入分辨率为$320 \times 320$。我们进行了基准测试并比较了mAP(COCO挑战度量标准),参数数量和Multiply-Adds数量。结果如表6所示。MobileNetV2 SSDLite不仅是最高效的模型,而且也是三者中最准确的模型。值得注意的是,MobileNetV2 SSDLite效率高20倍,模型要小10倍,但仍优于COCO数据集上的YOLOv2。
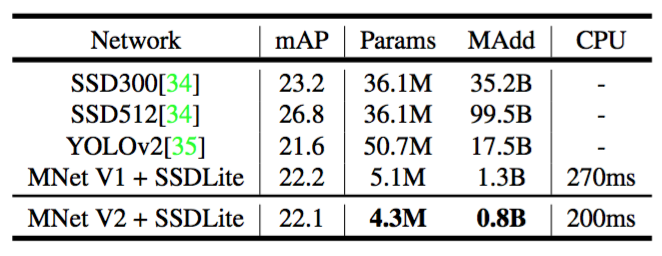
表6:MobileNetV2+SSDLite和其他实时检测器在COCO数据集目标检测任务中的性能比较。MobileNetV2+SSDLite以更少的参数和更小的计算复杂性实现了具有竞争力的精度。所有模型都在trainval35k上进行训练,并在test-dev上进行评估。SSD/YOLOv2的数字来自于[35]。使用内部版本的TF-Lite引擎,报告了在Google Pixel 1手机的大型核心上的运行时间。
6.3. 语义分割
在本节中,我们使用MobileNetV1和MobileNetV2模型作为特征提取器与DeepLabv3[39]在移动语义分割任务上进行比较。DeepLabv3采用了空洞卷积[40,41,42],这是一种显式控制计算特征映射分辨率的强大工具,并构建了五个平行头部,包括(a)包含三个具有不同空洞率的$3 \times 3$卷积的Atrous Spatial Pyramid Pooling模块(ASPP)[43],(b)$1 \times 1$卷积头部,以及(c)图像级特征[44]。我们用输出步长来表示输入图像空间分辨率与最终输出分辨率的比值,该分辨率通过适当地应用空洞卷积来控制。对于语义分割,我们通常使用输出$stride = 16$或$8$来获取更密集的特征映射。我们在PASCAL VOC 2012数据集[3]上进行了实验,使用[45]中的额外标注图像和评估指标mIOU。
为了构建移动模型,我们尝试了三种设计变体:(1)不同的特征提取器,(2)简化DeepLabv3头部以加快计算速度,以及(3)提高性能的不同推断策略。我们的结果总结在表7中。我们已经观察到:(a)包括多尺度输入和添加左右翻转图像的推断策略显著增加了MAdds,因此不适合于在设备上应用,(b)使用输出步长16比使用输出步长8更有效率,(c)MobileNetV1已经是一个强大的特征提取器,并且只需要比ResNet-101少约4.9-5.7倍的MAdd[8](例如,mIOU:78.56与82.70和MAdds:941.9B vs 4870.6B),(d)在MobileNetV2的倒数第二个特征映射的顶部构建DeepLabv3头部比在原始的最后一个特征映射上更高效,因为倒数第二个特征映射包含320个通道而不是1280个通道,这样我们就可以达到类似的性能,但是要比MobileNetV1的通道少2.5倍,(e)DeepLabv3头部的计算成本很高,移除ASPP模块会显著减少MAdd并且只会稍微降低性能。在表7末尾,我们鉴定了一个设备上的潜在候选应用(粗体),该应用可以达到$75.32\%$mIOU并且只需要2.75B MAdds。
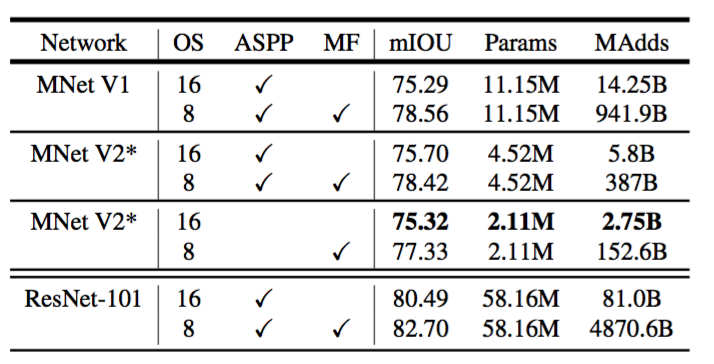
表7:PASCAL VOC 2012验证集上的MobileNet+DeepLabv3推断策略。MNet V2*:用于DeepLabv3头部的倒数第二个特征映射,其中包括(1)Atrous Spatial Pyramid Pooling(ASPP)模块和(2)$1\times 1$卷积以及图像池化功能。OS:控制分割映射输出分辨率的输出步长。MF:测试期间多尺度和左右翻转输入。所有的模型都在COCO上进行预训练。设备上的潜在候选应用以粗体显示。PASCAL图像的尺寸为$ 512 \ times 512 $,而空洞卷积使得我们可以在不增加参数数量的情况下控制输出特征分辨率。
6.4. 消融研究
倒置残差连接。残差连接的重要性已被广泛研究[8,30,46]。本文报告的新结果是连接瓶颈的快捷连接性能优于连接扩展层的的快捷连接(请参见图6b以供比较)。
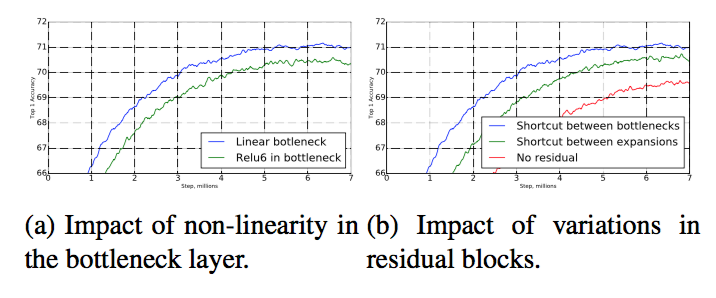
图6:非线性和各种快捷(残差)连接的影响。
线性瓶颈的重要性。线性瓶颈模型的严格来说比非线性模型要弱一些,因为激活总是可以在线性状态下进行,并对偏差和缩放进行适当的修改。然而,我们在图6a中展示的实验表明,线性瓶颈改善了性能,为非线性破坏低维空间中的信息提供了支持。
7. 总结及将来工作
我们描述了一个非常简单的网络架构,使我们能够构建一系列高效的移动模型。我们的基本构建单元具有多种特性,使其特别适用于移动应用。它允许非常有效的内存推断,并依赖利用所有神经框架中的标准操作。
对于ImageNet数据集,我们的架构改善了许多性能点的最新技术水平。对于目标检测任务,我们的网络在精度和模型复杂度方面都优于COCO数据集上的最新实时检测器。值得注意的是,我们的架构与SSDLite检测模块相比,计算量少20倍,参数比YOLOv2少10倍。
理论上:所提出的卷积块具有独特的属性,允许将网络表现力(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这个是未来研究的重要方向。
致谢
我们要感谢Matt Streeter和Sergey Ioffe的有益反馈和讨论。
References
[1] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision, 115(3):211–252, December 2015.
[2] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
[3] Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserma. The pascal visual object classes challenge a retrospective. IJCV, 2014.
[4] Mobilenetv2 source code. Available from https://github.com/tensorflow/ models/tree/master/research/slim/nets/mobilenet.
[5] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Bartlett et al. [48], pages 1106–1114.
[6] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
[7] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, pages 1–9. IEEE Computer Society, 2015.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015.
[9] James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13:281–305, 2012.
[10] Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practical bayesian optimization of machine learning algorithms. In Bartlett et al. [48], pages 2960–2968.
[11] Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat, and Ryan P. Adams. Scalable bayesian optimization using deep neural networks. In Francis R. Bach and David M. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, volume 37 of JMLR Workshop and Conference Proceedings, pages 2171–2180. JMLR.org, 2015.
[12] Babak Hassibi and David G. Stork. Second order derivatives for network pruning: Optimal brain surgeon. In Stephen Jose Hanson, Jack D. Cowan, and C. Lee Giles, editors, Advances in Neural Information Processing Systems 5, [NIPS Conference, Denver, Colorado, USA, November 30 - December 3, 1992], pages 164–171. Morgan Kaufmann, 1992.
[13] Yann LeCun, John S. Denker, and Sara A. Solla. Optimal brain damage. In David S. Touretzky, editor, Advances in Neural Information Processing Systems 2, [NIPS Conference, Denver, Colorado, USA, November 27-30, 1989], pages 598–605. Morgan Kaufmann, 1989.
[14] Song Han, Jeff Pool, John Tran, and William J. Dally. Learning both weights and connections for efficient neural network. In Corinna Cortes, Neil D. Lawrence, Daniel D. Lee, Masashi Sugiyama, and Roman Garnett, editors, Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 1135–1143, 2015.
[15] Song Han, Jeff Pool, Sharan Narang, Huizi Mao, Shijian Tang, Erich Elsen, Bryan Catanzaro, John Tran, and William J. Dally. DSD: regularizing deep neural networks with dense-sparse-dense training flow. CoRR, abs/1607.04381, 2016.
[16] Yiwen Guo, Anbang Yao, and Yurong Chen. Dynamic network surgery for efficient dnns. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors, Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pages 1379–1387, 2016.
[17] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. CoRR, abs/1608.08710, 2016.
[18] Karim Ahmed and Lorenzo Torresani. Connectivity learning in multi-branch networks. CoRR, abs/1709.09582, 2017.
[19] Tom Veniat and Ludovic Denoyer. Learning time-efficient deep architectures with budgeted super networks. CoRR, abs/1706.00046, 2017.
[20] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. CoRR, abs/1707.01083, 2017.
[21] Soravit Changpinyo, Mark Sandler, and Andrey Zhmoginov. The power of sparsity in convolutional neural networks. CoRR, abs/1702.06257, 2017.
[22] Min Wang, Baoyuan Liu, and Hassan Foroosh. Design of efficient convolutional layers using single intra-channel convolution, topological subdivisioning and spatial ”bottleneck” structure. CoRR, abs/1608.04337, 2016.
[23] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. CoRR, abs/1707.07012, 2017.
[24] Lingxi Xie and Alan L. Yuille. Genetic CNN. CoRR, abs/1703.01513, 2017.
[25] Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu, Jie Tan, Quoc V. Le, and Alexey Kurakin. Large-scale evolution of image classifiers. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 2902–2911. PMLR, 2017.
[26] Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. CoRR, abs/1611.01578, 2016.
[27] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam.
Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861, 2017.
[28] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[29] Dongyoon Han, Jiwhan Kim, and Junmo Kim. Deep pyramidal residual networks. CoRR, abs/1610.02915, 2016.
[30] Saining Xie, Ross B. Girshick, Piotr Dolla ́r, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. CoRR, abs/1611.05431, 2016.
[31] Martın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
[32] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embed- ding. arXiv preprint arXiv:1408.5093, 2014.
[33] Jonathan Huang, Vivek Rathod, Chen Sun, Men- glong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017.
[34] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In ECCV, 2016.
[35] Joseph Redmon and Ali Farhadi. Yolo9000: Better, faster, stronger. arXiv preprint arXiv:1612.08242, 2016.
[36] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.
[37] Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems, pages 379–387, 2016.
[38] Jonathan Huang, Vivek Rathod, Derek Chow, Chen Sun, and Menglong Zhu. Tensorflow object detection api, 2017.
[39] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. CoRR, abs/1706.05587, 2017.
[40] Matthias Holschneider, Richard Kronland-Martinet, Jean Morlet, and Ph Tchamitchian. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets: Time-Frequency Methods and Phase Space, pages 289–297. 1989.
[41] Pierre Sermanet, David Eigen, Xiang Zhang, Michaël Mathieu, Rob Fergus, and Yann LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv:1312.6229, 2013.
[42] George Papandreou,Iasonas Kokkinos, and Pierre Andre Savalle. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In CVPR, 2015.
[43] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2017.
[44] Wei Liu, Andrew Rabinovich, and Alexander C. Berg. Parsenet: Looking wider to see better. CoRR, abs/1506.04579, 2015.
[45] Bharath Hariharan, Pablo Arbeláez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In ICCV, 2011.
[46] Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. CoRR, abs/1602.07261, 2016.
[47] Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14, pages 2924–2932, Cambridge, MA, USA, 2014. MIT Press.
[48] Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Léon Bottou, and Kilian Q. Weinberger, editors. Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States, 2012.

