文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
本文为美团文章学习的笔记整理。
1. 背景
ETA(Estimated Time of Arrival,“预计送达时间”),即用户下单后,配送人员在多长时间内将外卖送达到用户手中。送达时间预测的结果,将会以”预计送达时间”的形式,展现在用户的客户端页面上,是配送系统中非常重要的参数,直接影响了用户的下单意愿、运力调度、骑手考核,进而影响用户和骑手体验,以及配送系统的整体效率。
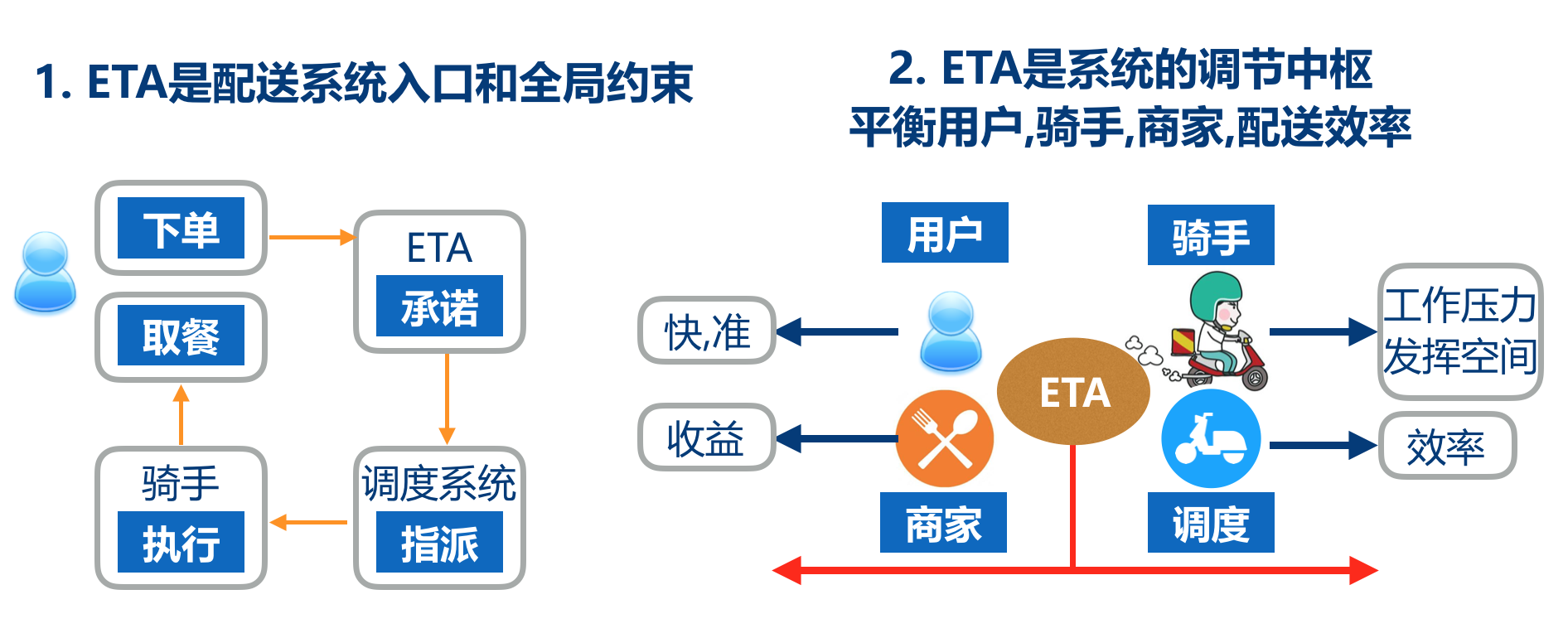
对于整个配送系统而言,ETA既是配送系统的入口和全局约束,又是系统的调节中枢。具体体现在:
- ETA在用户下单时刻就需要被展现,这个预估时长继而会贯穿整个订单生命周期,首先在用户侧给予准时性的承诺,接着被调度系统用作订单指派的依据及约束,而骑手则会参考ETA时间作为考核时间执行订单的配送。
- ETA作为系统的调节中枢,需要平衡用户-骑手-商家-配送效率。从用户的诉求出发,尽可能快和准时,从骑手的角度出发,ETA太短会增大其配送难度。从调度角度出发,太长或太短都会影响配送效率。而从商家角度出发,都希望订单被尽可能派发出去,因为这关系到商家的收入。
外卖场景的ETA面临如下的挑战:
- 外卖场景中ETA是对客户履约承诺的重要组成部分,无论是用户还是骑手,对于ETA准确性的要求非常高。
- 由于外卖ETA承担着承诺履约的责任,因此是否能够按照ETA准时送达,也是外卖骑手考核的指标、配送系统整体的重要指标;承诺一旦给出,系统调度和骑手都要尽力保证准时送达。因此过短的ETA会给骑手带来困难,并降低调度合单能力、降低配送效率;过长的ETA又会很大程度影响用户体验。
- 外卖场景中ETA包含更多环节,骑手全程完成履约过程,其中包括到达商家、商家出餐、等待取餐、路径规划、不同楼宇交付等较多的环节,且较高的合单率使得订单间的流程互相耦合,不确定性很大,做出合理的估计也有更高难度。
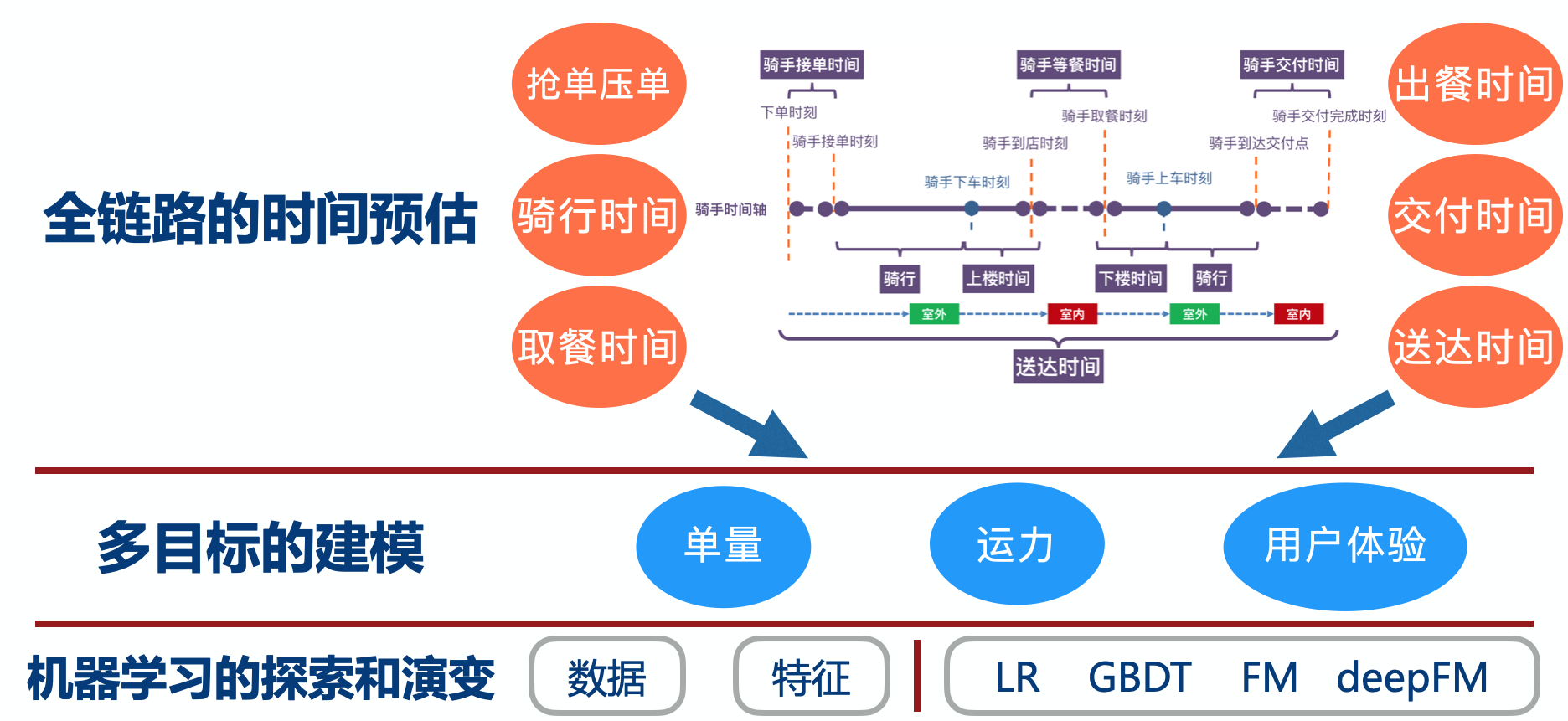
下图是骑手履约全过程的时间轴,过程中涉及各种时长参数,可以看到有十几个节点,其中关键时长达到七个。对于ETA建模,不光是简单一个时间的预估,更需要的是全链路的时间预估,同时更需要兼顾”单量-运力-用户体验”之间的平衡。配送ETA的演变包括了数据、特征层面的持续改进,也包括了模型层面一路从LR-XGB-FM-DeepFM-自定义结构的演变。
Note:
ETA一旦展示给用户,就意味着对用户进行了承诺,影响范围是巨大的。系统调度和骑手,都要尽力保证准时送达。
2. 业务流程迭代中的模型改进
2.1 基础模型迭代及选择
与大部分CTR模型的迭代路径相似,配送ETA模型的业务迭代经历了LR->树模型->Embedding->DeepFM->针对性结构修改的路径。特征层面也进行不断迭代和丰富。
- 模型维度从最初考虑特征线性组合,到树模型做稠密特征的融合,到Embedding考虑ID类特征的融合,以及FM机制低秩分解后二阶特征组合,最终通过业务指标需求,对模型进行针对性调整。
- 特征维度逐步丰富到地址特征/轨迹特征/区域特征/时间特征/时序特征/订单特征等维度。
目前,版本模型在比较了Wide &Deep、DeepFM、AFM等常用模型后,考虑到计算性能及效果,最终选择了DeepFM作为初步的Base模型。整个DeepFM模型特征Embedding化后,在FM(Factorization Machine)基础上,进一步加入deep部分,分别针对稀疏及稠密特征做针对性融合。FM部分通过隐变量内积方式考虑一阶及二阶的特征融合,DNN部分通过Feed-Forward学习高阶特征融合。模型训练过程中采取了Learning Decay/Clip Gradient/求解器选择/Dropout/激活函数选择等。
Note:
ETA预测选择了DeepFM作为深度学习Base模型。
2.2 损失函数
在ETA预估场景下,准时率及置信度是比较重要的业务指标。初步尝试将Square的损失函数换成Absolute的损失函数,从直观上更为切合MAE相比ME更为严苛的约束。在适当Learning Decay下,结果收敛且稳定。
在迭代中考虑到相同的ETA承诺时间下,在前后N分钟限制下,预估偏短1min的用户、骑手体验明显差于预估偏长1分钟的体验。因此损失函数的设计需要考虑到偏短偏长的差异。适当降低偏长部分的损失,提高偏短部分的损失。进行多次调试设计后,最终确定以前后N分钟以及原点作为3个分段点。在原先absolute函数优化的基础上,在前段设计1.2倍斜率absolute函数,后段设计1.8倍斜率absolute函数,以便让结果整体往中心收敛,且更倾向于适度偏长预估,保障用户和骑手体验,对于ETA各项指标均有较大幅度提升。
Note:
这个损失函数是为深度学习模型设计的,其它模型不一定适用,但考虑偏短偏长差异的思想可以借鉴。
2.3 业务规则融入模型
目前的业务架构是“模型+规则”,在模型预估一个ETA值之后,针对特定业务场景,会有特定业务规则时间叠加以满足特定场景需求,例如在冬至时饺子品类的需求暴增,模型可能捕捉不到这样的异常点,因此需要规则对异常情况做时间保护。各项规则由业务指标多次迭代产生。在模型时间和规则时间分开优化后,即模型训练时并不能考虑到规则时间的影响,而规则时间在一年之中不同时间段,会产生不同的浮动,在经过一段时间重复迭代后,会加大割裂程度。
Note:
业务架构:模型+规则,ETA与业务是紧密结合的,模型是一个初步的结果,不同的场景需要根据业务进行适当的调整。
在尝试了不同方案后,最终将整体规则写入到了TF模型中,在TF模型内部调整整体规则参数。
- 对于简单的(ab+c)d等规则,可以将规则逻辑直接用TF的OP算子来实现,比如当b、d为定值时,则a、c为可学习的参数。
- 对于过于复杂的规则部分,则可以借助一定的模型结构,通过模型的拟合来代替,过多复杂OP算子嵌套并不容易同时优化。
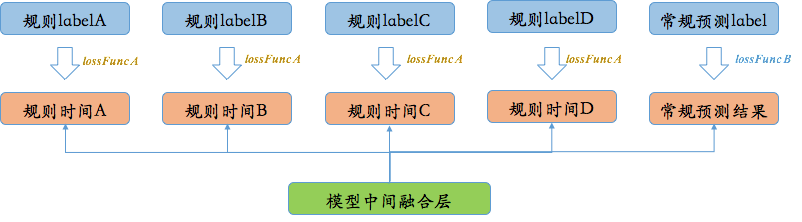
通过调节不同的拟合部分及参数,将多个规则完全在TF模型中实现。最终对业务指标具备很大提升效果,且通过对部分定值参数的更改,具备部分人工干涉模型、对骑手体验做兜底保障的能力。整体架构简化为多目标预估的架构,这里采用多任务架构中常用的Shared Parameters的结构,训练时按比例采取不同的交替训练策略。结构上从最下面的模型中间融合层出发,分别在TF内实现常规预测结构及多个规则时间结构,而其对应的Label则仍然从常规的历史值和规则时间值中来,这样考虑了以下几点:
- 模型预估时,已充分考虑到规则对整体结果的影响(例如多个规则的叠加效应),作为整体一起考虑。
- 规则时间作为辅助Label传入模型,对于模型收敛及Regularization,起到进一步作用。
- 针对不同的目标预估,采取不同的Loss,方便进行针对性优化,进一步提升效果。
Note:
初期可以使用模型+规则,后期规则融合进深度模型,会有大的提升。
2.4 缺失值处理
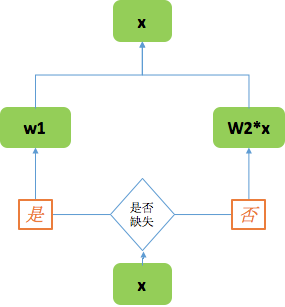
对于特征x进入TF模型,进行判断,如果是缺失值,则设置w1参数,如果不是缺失值则进入模型数值为w2 *x,这里将w1和w2作为可学习参数,同时放入网络进行训练。以此方法来代替均值/零值等作为缺失值的方法。
3. 长尾问题优化
3.1 模型预估结果+长尾规则补时
基础模型学习的是整体的统计分布,但对于一些长尾情形的学习并不充分,体现在长尾情形下预估时间偏短(由于骑手的考核时间参考ETA制定,ETA预估偏短会增大骑手的配送难度)。故将长尾拆解成两部分来分析:
- 业务长尾,即整体样本分布造成的长尾。主要体现在距离、价格等维度。距离越远,价格越高,实际送达时间越长,但样本占比越少,模型在这一部分上的表现可能偏短。
- 模型长尾,即由于模型自身对预估值的不确定性造成的长尾。模型学习的是整体的统计分布,但不是对每个样本的预估都有“信心”。实践中采用RF多棵决策树输出的标准差来衡量不确定性。RF模型生成的决策树是独立的,每棵树都可以看成是一个专家,多个专家共同打分,打分的标准差实际上就衡量了专家们的“分歧”程度(以及对预估的“信心”程度)。随着RF标准差的增加,模型的置信度和准时率均在下降。
在上述拆解下,采用补时规则来解决长尾预估偏短的问题:长尾规则补时为 <业务长尾因子 , 模型长尾因子> 组合。其中业务长尾因子为距离、价格等业务因素,模型长尾因子为RF标准差。最终的ETA策略即为模型预估结果+长尾规则补时,较好的保证了长尾情况的骑手体验。
Note:
在模型预估结果的基础上,加上长尾规则补时来解决长尾预测时间偏短问题。
4. 工程开发实践
4.1 训练部分实践
整体训练流程
对于线下训练,采取如下训练流程:
Spark原始数据整合 -> Spark生成TFRecord -> 数据并行训练 -> TensorFlow Serving线下GPU评估 -> CPU Inference线上预测
数据并行训练方式
整个模型的训练在平台上进行,先后尝试分布式方案及单机多卡方案。线上模型生产采用单机多卡方案进行例行训练。
TF模型集成预处理
为了简化工程开发中的难度,在模型训练时,考虑将所有的预处理文件写入TF计算图之中,每次在线预测只要输入最原始的特征,不经过工程预处理,直接可得到结果。
4.2 TF模型线上预测
略

