文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
本文为DoorDash文章学习的笔记整理。
Managing Supply and Demand Balance Through Machine Learning
At DoorDash, we want our service to be a daily convenience offering timely deliveries and consistent pricing. Achieving these objectives requires a good balance between the supply of Dashers (our term for delivery drivers) and the demand for orders.
DoorDash希望服务能够提供及时交付和一致的定价。实现这些目标需要在Dashers(配送员)供应和订单需求之间取得良好的平衡。
During periods of high demand we generally increase pay, providing an incentive to ensure enough Dashers are available for consumers to receive their orders as quickly as possible. We do not pass through this increased pay to consumers, who will pay the same fees no matter the time of day.
在需求旺盛的时期,通常会增加配送费以确保有足够的Dasher可供消费者尽快收到他们的订单。DoorDash不会将这种增加的报酬转嫁给消费者,无论何时,消费者都会支付相同的费用。
Note:
DoorDash在需求旺盛时会提高配送费用,且这种成本没有转嫁给消费者,这意味着配送成本变高,但有更好的用户体验。
Given the complexity of offering Dashers peak demand pay, we built a new mobilization system that allocates incentives ahead of any anticipated supply and demand imbalance. When building this system, we focused on the following things:
- Defining our supply and demand measurement metrics and project objectives clearly
- Generating high-fidelity forecasts for supply and demand
- Setting up a new optimization process for incentive allocation under constraints
- Managing uncertainty
- Improving reliability and maintainability of the system
考虑到给予Dashers高峰需求配送费的复杂性,DoorDash建立了一个新的调度系统,在任何预期的供需失衡之前分配奖励。在构建这个系统时,专注于以下几点:
- 明确定义供需度量指标和项目目标
- 生成高置信度的供需预测
- 建立约束下激励分配的新优化流程
- 管理不确定性
- 提高系统的可靠性和可维护性
How do we quantify supply and demand imbalance?
When outlining the problem of supply and demand imbalance, it is useful to adopt the context of all the affected parties:
- For consumers, a lack of Dasher availability during peak demand is more likely to lead to order lateness, longer delivery times, or inability to request a delivery and having to opt for pick up.
- For Dashers, a lack of orders leads to lower earnings and longer and more frequent shifts in order to hit personal goals.
- For merchants, an undersupply of Dashers leads to delayed deliveries, which typically results in cold food and a decreased reorder rate.
在概述供需失衡问题时,采用所有受影响方的背景是有用的:
- 对于消费者而言,在需求高峰期间,缺少可用Dasher更有可能导致订单延迟、更长的交付时间、或者无法请求配送并不得不选择(自己)取货。
- 对于Dasher来说,订单不足会导致收入降低,并且为了实现个人目标而需要更长、更频繁的移动。
- 对于商家来说,Dasher供应不足会导致延迟交付,这通常会导致食物变凉和复购率下降。
With this context, it becomes clear that the ideal scenario would be to have a system that balances supply and demand at a delivery level instead of market level, but this is not realistic when choosing market-measurement metrics. Balancing at the delivery level means every order has a Dasher available at the most optimal time and every Dasher hits their pay-per hour target.
在这种情况下,很明显,理想情况是有一个可以在配送层面而不是市场层面来平衡供需的系统,但这在选择市场度量指标时是不现实的。配送层面的平衡意味着每个订单在最佳时间都有一个可用的Dasher,并且每个Dasher都达到了他们的时薪目标。
In contrast, market-level balance means there are relatively equal numbers of Dashers and orders in a market but there are not necessarily optimal conditions for each of these groups at the delivery level. In practice, the variance level for supply and demand driven by Dasher and consumer preferences and other changing conditions in the environment, such as traffic and weather, make it difficult to balance supply and demand at the delivery level. Hence, we focused on market-level metrics to define the state of each market, even though a delivery-level metric would have provided a more ideal outcome.
相比之下,市场层面的平衡意味着市场中Dasher和订单的数量相对相等,但在交付层面上,这些组中的每一个都不一定存在最佳条件。在实践中,供需差异水平受Dasher和消费者偏好,以及环境中的其他变化条件(如交通和天气)驱动,使得很难在交付层面来平衡供需。因此,DoorDash专注于市场层面的指标来定义每个市场的状态,即使交付层面的指标会提供更理想的结果。
Note:
从市场层面来度量供需,即Dashe数量和订单数量。
For our primary supply and demand measurement metric, we looked at the number of hours required to make deliveries while keeping delivery durations low and Dasher busyness high. By focusing on hours, we can account for regional variation driven by traffic conditions, batching rates, and food preparation times.
对于主要的供需度量指标,DoorDash查看了在保持交付持续时间短和Dasher繁忙程度高的情况下,交付所需的小时数。通过关注小时数,可以解释由交通状况、批配送率(多单同时进行)和食物准备时间引起的区域变化。
To understand how this metric would work in practice let’s consider an example. Let’s imagine that it is Sunday at dinner time in New York City, and we estimate that 1,000 Dasher hours are needed to fulfill the expected demand. We might also estimate that unless we provide extra incentives, only 800 hours will likely be provided by Dashers organically. Without mobilization actions we would be undersupplied by about 200 hours.
为了理解这个指标在实际中是如何工作的,考虑一个例子。假设现在是纽约市周日的晚餐时间,估计需要1000 Dasher小时才能满足预期需求。还可以估计,除非提供额外的激励措施,否则Dasher可能只会有组织地提供800小时。如果没有调动行为,将缺乏约200小时。
We generally compute this metric where Dashers sign up to Dash and to time units that can span from hourly durations to daypart units like lunch and dinner. It is very important to not select an aggregation level that can lead to artificial demand and supply smoothing. For example, within a day we might be oversupplied at breakfast and undersupplied at dinner. Optimizing for a full day would lead to smoothing any imbalance and generate incorrect mobilization actions.
通常在Dasher注册Dash时计算这个指标,时间单元可以从按小时的持续时间到午餐和晚餐等时段单元。不要选择可能导致人为需求和供应平滑的聚合级别,这一点非常重要。 例如,在一天之内,可能在早餐时供应过剩,而在晚餐时供应不足。优化一整天会导致平滑任何不平衡并产生不正确的调动行为。
Note:
优化特定的时间段,按小时和时间段都可以,但不能优化一整天。
Once we decide on the health metric and the unit at which we take actions, we proceed with balancing supply and demand through adjustments to supply. Our team generally adjusts the supply side of the market by offering incentives to increase Dasher mobilization when there is more demand. Through incentives, we provide Dashers a guarantee that they will earn a fixed amount of money on any delivery they accept in a specific region-time unit. We will describe in the following section how forecasting and optimization plays a role in that.
一旦确定了运行指标和采取行动的时间单元,就会通过调整供应来平衡供需。当需求更多时,通常通过提供激励措施来调整市场的供给端,以增加Dasher的调动。通过激励措施,向Dasher保证,他们将在特定区域时间单元内在任何交付中赚取固定金额的钱。将在下一节中描述预测和优化如何在其中发挥作用。
How do we forecast supply and demand at a localized level?
Now that we have a metric to measure supply and demand levels, a unit of region/time to take actions, and actions we take to manage supply, we can determine our forecasting requirement details and how we forecast each market’s supply and demand conditions.
现在有了度量供需水平的指标、采取行动的地区/时间单元以及为管理供给而采取的行动,可以确定预测需求细节以及如何预测每个市场的供需状况。
Defining forecasting requirements
Given that the forecasts we generate are meant to be used in an automated system, both the algorithm we use for forecasting and the subsequent library ecosystem we would rely on can have a large impact on maintaining automation in the long run. We primarily reformulated the forecasting problem into a regression problem and used gradient boosting through the Microsoft-developed open source LightGBM framework. There are a couple of reasons behind this choice.
由于生成的预测要用于自动化系统中,从长远来看,用于预测的算法和将依赖的后续库生态系统都可能对自动化系统的维护有很大影响。DoorDash主要将预测问题重新表述为回归问题,并通过微软开发的开源LightGBM框架使用梯度提升。这种选择背后有几个原因。
Support for multivariate forecasting
Many univariate forecasting approaches do not scale well when it comes to generating thousands of regional forecasts with low-level granularity. Our experience strongly supports the thesis that some of the best models are created through a process of rapid prototyping, so we looked for approaches where going from hypothesizing a model improvement to having the final result can be done quickly. LightGBM can be used to train and generate thousands of regional forecasts within a single training run, allowing us to very quickly iterate on model development.
在碰到生成数千个低粒度区域预测时,许多单变量预测方法无法很好地扩展。一些最佳模型是通过快速原型制作过程创建的,DoorDash的经验强烈支持这个论点,因此寻找可以快速完成从假设模型改进到获得最终结果的方法。LightGBM可用于在一次训练运行中训练和生成数千个区域预测,使开发人员能够非常快速地迭代模型开发。
Support for extrapolation
As DoorDash expands both nationally and internationally, we need our forecasting system to be able to generate some expectations for how our supply and demand growth would look in places where we don’t currently offer our services. For example, if we launch in a new city, we can still make reasonable projections regarding the supply and demand trajectory even with no historical data. Deep learning and traditional machine learning (ML)-based approaches work particularly well in this case, since latent information that helps with extrapolation can either be learned through embedding vectors or through good feature engineering. Information about population size, general traffic conditions, number of available merchants, climate, and geography can all be used to inform extrapolation.
随着DoorDash在国内和国际上的扩张,DoorDash需要预测系统能够对目前不提供服务的地方的供需增长情况生成一些预期。例如,如果在一个新城市启动服务,即使没有历史数据,DoorDash仍然可以对供需发展轨迹做出合理的预测。在这种情况下,深度学习和基于传统机器学习(ML)的方法效果特别好,因为有助于推断的潜在信息可以通过嵌入向量或良好的特征工程来学习。有关人口规模、一般交通状况、可用商户数量、气候和地理的信息都可用于推断。
Support for counterfactuals
Forecasts are used to set an expectation of what will happen but they are also inevitably used to guide the decision-making process. For example, our stakeholders would ask us how conditions would change if we changed incentive levels in our supply forecast model so that we can understand how to make tradeoffs between supply and costs. These types of counterfactuals are very helpful not only in forecasting what we think will happen, but in also estimating the impact of actions we are going to take. In LightGBM, approximate counterfactuals can be generated by changing the inputs that go into the model at inference time.
预测用于设定对将要发生什么的预期,但它们也不可避免地用于指导决策过程。例如,股东会问如果改变供应预测模型中的激励水平,情况会如何变化,以便了解如何在供应和成本之间进行权衡。这些类型的反事实不仅在预测会发生什么方面非常有帮助,而且在评估要采取的行动的影响方面也非常有帮助。在LightGBM中,可以通过在推断时更改进入模型的输入来生成近似反事实。
Small dependency footprint
We wanted the forecasting system to have a minimal dependency footprint, meaning that we were not overly reliant on a host of third-party libraries. This requirement immediately removed a lot of the auto-forecasting approaches, where installing one library often meant installing 100-plus additional libraries, or approaches that provided unified toolkits and had a large number of transitive dependencies. A bloated footprint creates compatibility issues, upgrade challenges, and a large exposure area to security vulnerabilities. LightGBM has a very small dependency footprint, and it is relatively painless to perform upgrades.
DoorDash希望预测系统具有极少的依赖资源,这意味着不会过度依赖大量第三方库。这一要求立刻移除了许多自动预测方法,安装一个库经常意味着安装 100多个额外的库,或者提供统一工具包并具有大量传递依赖项的方法。庞大的资源占用会导致兼容性问题、升级挑战以及安全漏洞的大面积暴露。LightGBM的依赖资源非常少,执行升级也相对轻松。
Thriving community
Lastly, we wanted to rely on an ecosystem with a thriving community and a strong core maintainer group. Maintaining an open source library is challenging. A library might be created by a graduate student or one to three core developers working within a company. Nonetheless, folks find new interests, new jobs, switch jobs, find new careers, or abandon careers. Keeping track of issues and bugs related to a library is often not a priority a few years or months down the line. This eventual lack of support then forces users to create internal forks in order to adopt the forecast tooling for their use cases or engage in a complete remodelling exercise. For these reasons, when selecting a tool, we looked at metrics like release cycles, number of stars, and community involvement to ensure there would be good community maintenance into the future.
最后,DoorDash希望依靠一个拥有蓬勃发展的社区和强大的核心维护组的生态系统。维护一个开源库是一项挑战。一个库可能由研究生或公司内的一到三个核心开发人员创建。尽管如此,人们还是会找到新的兴趣、新的工作、换工作、寻找新的职业或放弃职业。跟踪与库相关的问题和错误通常不是几年或几个月后的优先事项。 这种最终缺乏支持会迫使用户创建内部分支,以便为其用例采用预测工具或进行完整的重构练习。出于这些原因,在选择工具时,DoorDash会查看发布周期、Star数和社区参与度等指标,以确保未来有良好的社区维护。
Forecasting with ML
Forecasting in the context of a pure regression problem can have it’s challenges, one of which has to do with understanding the data generation process and the causality between the inputs and outputs. For example, Figure 1, below, shows how our incentives relate to the growth in the number of Dasher hours.
在纯回归问题的背景下进行预测可能会遇到挑战,挑战之一与理解数据生成过程以及输入和输出之间的因果关系有关。例如,下面的图1显示了激励措施如何与Dasher工作小时数的增长相关联。
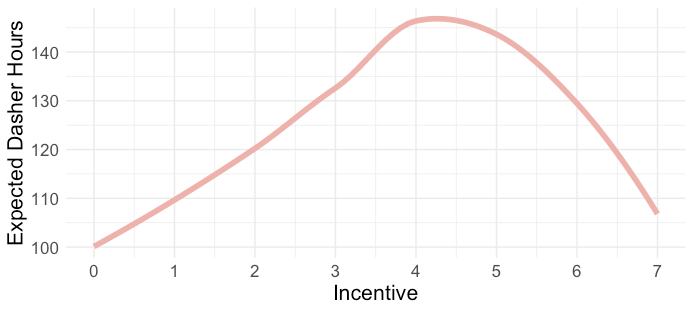
Figure 1: This data suggests that there is a non-linear relationship between incentives and mobilization, with higher incentives seeing an increase in Dasher hours and very high incentives related to a dramatic drop in hours. This counterintuitive relationship can often be a sign of either an omitted variable bias or simultaneous causality bias.
图 1:该数据表明,激励和Dasher调动之间存在非线性关系,较高的激励会导致Dasher工作小时数增加,非常高的激励会导致工作小时数急剧下降。 这种违反直觉的关系通常可能是遗漏变量偏差或同时存在因果关系偏差的标志。
If we blindly rely on the model to learn causality through correlations found in the data, we would’ve created a system that would mistakenly assume that providing very high incentive levels would lead to fewer Dashers on the road. A causal interpretation, where high growth incentives would lead to a decrease in mobilization would be nonsensical.
如果盲目地依赖模型通过数据中的相关性来学习因果关系,就会创建一个系统,错误地认为提供非常高的激励水平会导致路上的Dasher数量更少。 高增长激励会导致调动减少的因果解释是荒谬的。
It is more likely that the model is simply missing a confounding variable. For example, in periods associated with bad weather or holidays, Dashers want to spend time inside or with their families. We are more likely to see a decrease in availability during these times, triggering our supply and demand systems to offer higher incentives to keep the market balanced.
这个模型更有可能只是缺少一个混合变量。例如,在涉及恶劣天气或假期的时候,Dasher希望呆在家里或与家人共度时光。在这些时间,更有可能看到可用Dasher数量下降,触发供需系统提供更高的激励措施以保持市场平衡。
A model lacking knowledge of weather or holidays might learn that high incentives lead to fewer Dasher hours, when the causal relationship is simply missing a covariate link. This example illustrates why it becomes important to figure out a way to sometimes constrain relationships found in the data through domain knowledge, or to rely on experimental results to regularize some correlational relationships identified by the model and not blindly apply the algorithm to the available data.
缺乏天气或假期知识的模型可能会学习到高激励会导致更少的Dasher小时数,而因果关系只是缺少协变量链接。这个例子说明了为什么有时通过领域知识找出一种方法来约束数据中发现的关系,或者依靠实验结果来规范模型识别的一些相关关系而不是盲目地将算法应用于可用数据变得很重要。
A second challenge has to do with a common truism found in forecasting, which is that the unit of forecasting needs to match the context at which decisions are made. It can be tempting to forecast even more granularly, but that is generally a bad idea. This can be easily demonstrated through a simulation.
第二个挑战与预测中的一个普遍真理有关,即预测单元需要与做出决策的环境相匹配。进行更精细的预测可能很诱人,但这通常是一个坏主意。通过仿真这可以很容易地证明。
Consider the following three sub-regions describing daily demand by drawing samples, as shown in Figure 2, below, from a normal distribution with a mean of 100 and standard deviation of 25, giving us a coefficient of variation of 25%. When we aggregate these regions, we simply sum the expected mean to get an expected aggregate demand of 300. Nonetheless, the combined standard deviation is not equal with the sum of standard deviations but with the sum of the variances $\sqrt {3*25} = 43.3$, which gives us a coefficient of variation of the combined forecast of 14.4%. By simply aggregating random variables, we were able to reduce variance with respect to the mean by over 40%.
考虑下面三个通过抽取样本来描述每日需求的子区域,如下面的图2所示,它们来自均值为100、标准差为25的正态分布,变异系数为25%。当聚合这些区域时,简单累加预期均值得到期望总需求300。然而,组合的标准差不等于标准差之和,而是等于方差之和$\sqrt {3*25} = 43.3$,组合预测的变异系数为14.4%。通过简单地聚合随机变量,能够将均值的方差减少40%以上。
Although data aggregations can help with getting more accurate global forecasts, actions done on aggregated data can lead to inefficient mobilization. It is best to go for a solution where the unit of forecasting matches the unit of decision making.
尽管数据聚合有助于获得更准确的全局预测,但对聚合数据采取的行动可能会导致动员效率低下。 最好选择预测单位与决策单位相匹配的解决方案。
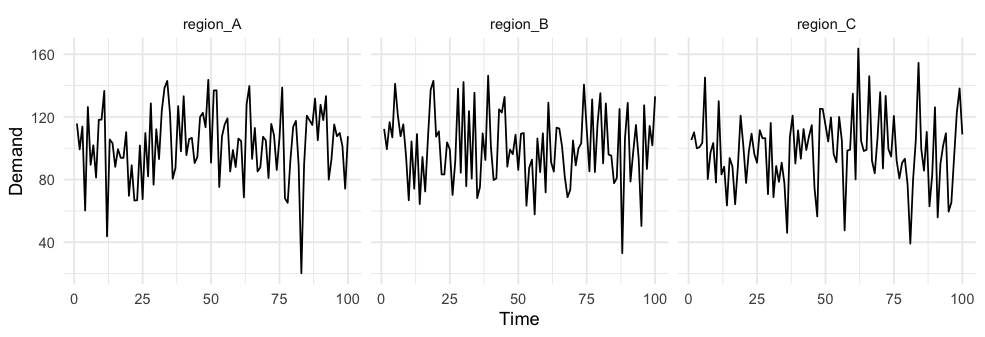
Figure 2: The top panel shows demand for three subregions. The bottom panel simply represents the aggregate demand. The relative variance in the bottom panel is reduced by 40% by performing aggregation of random variables.
图2:上部分显示了对三个子区域的需求。下部分仅表示总需求。通过执行随机变量的聚合,下部分的相对方差减少了40%。
Choosing an optimizer
One benefit of using ML algorithms is that they provide more accurate expectations of what will happen given the input data. Nonetheless, ML algorithms are often simply a building block in a larger system that consumes predictions and attempts to generate a set of optimal actions. Mixed-integer programming (MIP) or reinforcement learning (RL)-based solutions are great in building systems that focus on reward maximization under specific business constraints.
使用ML算法的一个好处是,在给定输入数据的情况下,它们可以对会发生什么提供更准确地预期。尽管如此,ML算法通常只是更大系统中的一个构建块,系统使用预测并尝试生成一组最佳操作。在构建专注于特定业务约束下实现奖励最大化的系统时,基于混合整数规划(MIP)或强化学习(RL)的解决方案是非常好的。
We decided to pursue a MIP approach given that it was easy to formalize, implement, and explain to stakeholders, and we have a lot of expertise in the domain. The optimizer has a custom objective function of minimizing undersupply with several constraints. The objective itself is very flexible and can be specified to favor either profitability or growth, depending on the business requirements. In the optimizer, we generally encoded a few global constraints:
- Never allocate more than one incentive in a particular region-time unit.
- Never exceed the maximum allowable budget set by our finance and operations partners.
DoorDash决定采用MIP方法,因为它易于形式化、实现和向股东解释,而且在该领域有很多专业知识。优化器有一个定制的目标函数,可以在几个约束下最小化供给不足。目标本身非常灵活,可以根据业务需求指定为有利于盈利能力或增长。在优化器中,通常编码一些全局约束:
- 切勿在特定区域时间单元分配多个奖励。
- 切勿超过财务和运营合作伙伴的最大允许预算。
Depending on requirements, we might also have different regional or country constraints, such as having different budgets, custom penalties, exclusion criteria for which units should not be included in the optimization, or incentive constraints that are guided by variability of the inputs.
根据要求,可能还会有不同的区域或国家限制,例如不同的预算、定制惩罚、不应该包括在优化中的单元排除标准,或者由输入变化引导的激励限制。
Dealing with uncertainty
Uncertainty in the inputs plays an important role in how the optimizer allocates incentives when resources are limited. To demonstrate, Figure 3, below, displays the distribution of the hypothesized supply and demand imbalance in two cities.
在资源有限时,输入的不确定性在优化器如何分配激励中起着重要作用。为了证实这一点,下面的图3显示了两个城市假设的供需失衡分布。
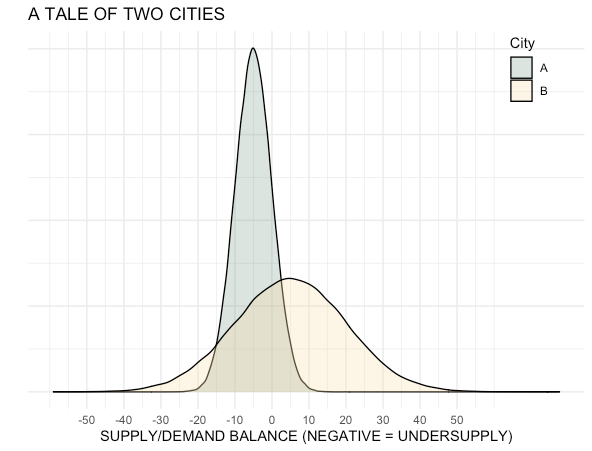
Figure 3: In City A, we believe that we will be undersupplied and are also generally confident in our prediction. In City B, our mean prediction is that we will be slightly oversupplied, but we are less certain in our estimate and there is some likelihood of experiencing large undersupply.
图3:在A市,DoorDash认为将供给不足,并且对其预测也普遍充满信心。在B市,平均预测是将略微供过于求,但对评估不太确定,并且有可能出现严重的供给不足。
If the optimizer knows nothing about uncertainty, it ends up with two issues. First, it will lack understanding that supply and demand balance can go from a spectrum of extreme undersupply to extreme oversupply. If the optimizer is set up to optimize under some preset thresholds, it would miss the chance to optimize for City B because the mean of the distribution is above zero.
如果优化器对不确定性一无所知,那么最终会出现两个问题。首先,它将缺乏对供需平衡可以从极端供应不足到极端供应过剩的认识。如果优化器设置为在某些预设阈值下进行优化,它将错过为城市B优化的机会,因为分布的均值高于零。
The second issue is that it would end up over-allocating resources in places where our forecasts are uncertain. Our forecasts tend to be noisiest in the long tail of small regions that have few Dashers and few orders. Because the count of these regions is large and they exhibit high variance, if we don’t explicitly account for this uncertainty we are more likely to generate estimates that by chance will have high undersupply, and thus over-allocate incentives to places that exhibit high variance relative to places that have low variance.
第二个问题是,它最终会在预测不确定的地方过度分配资源。在Dasher和订单很少的小区域的长尾,预测往往噪声最强。因为这些地区的数量很大并且它们表现出很大的方差,如果不明确考虑这种不确定性,更有可能产生偶然会严重供应不足的估计,会在表现出高方差的地区(相比于低方差地区)过度分配激励措施。
To address the issue of variance, we generate expected estimates of hours gap from forecasts using a resampling process. By performing resampling, we essentially measure the impact of undersupply in the context of the likelihood of that happening. For example, in Figure 3, above, City B has only a 34% chance of being undersupplied. However, if that happens, we can more accurately estimate the impact of sizable changes in undersupply. Either of these approaches lead to a more optimal decision in incentive allocation instead of simply using mean estimates from upstream forecasting inputs.
为了解决方差问题,使用重采样过程从预测中生成期望的小时差估计值。通过执行重采样,基本上度量了发生供应不足可能性的影响。例如,在上面的图3中,B市供应不足的可能性只有34%。但是,如果发生这种情况,可以更准确地评估在供应不足的地区发生重大变化的影响。这些方法中的任何一种都可以在激励分配中做出更优的决策,而不是简单地使用来自上游预测输入的平均估计。
Reliability and maintainability improvements
DoorDash has grown tremendously in the last year. More than 70% of the people at DoorDash joined in the 2020-21 period. This generally brought a wave of new engineering, product, platform, and infrastructure-related projects to help with continued growth, expansion, and scalability. For example, we had dozens of internal projects that related to breaking down our monolith and adopting a more microservice oriented architecture. We had hundreds of small and large projects related to product improvements or new vertical launches. Many of these projects came with changes in our data models and in our data generation and collection processes. Unfortunately, ML models can be terribly unreliable when the ecosystem for how data gets produced and exposed is constantly shifting, so we needed to make some changes to enhance the reliability of our system.
DoorDash在去年取得了巨大的增长。DoorDash超过70%的人在2020-21年期间加入。这通常会带来一波新的工程、产品、平台和基础设施相关项目,以帮助实现持续增长、扩张和可扩展性。例如,DoorDash有几十个内部项目,这些项目与打破单体架构并采用更加面向微服务的架构有关。DoorDash有数百个与产品改进或新的垂直发布相关的大小项目。其中许多项目伴随着数据模型、数据生成和收集过程的变化。不幸的是,当数据生成和数据暴露的生态系统不断变化时,ML模型可能非常不可靠,因此需要进行一些更改以增强系统的可靠性。
Decoupling data dependency chains
We could use many different data sources and encode hundreds of features to build a model that has high performance. Although that choice is very appealing and it does help with creating a model that performs better than one that has a simple data pipeline, in practice it creates a system that lacks reliability and generates a high surface area for feature drift, where the distribution of the inputs changes over time. Hence, when building our forecasting models, we went for simplicity and reliability first. This strategy also helped us move more quickly towards creating an end-to-end mobilization system.
DoorDash可以使用许多不同的数据源并编码数百个特征来构建具有高性能的模型。尽管这种选择非常吸引人,而且它确实有助于创建一个性能比具有简单数据流程的模型更好的模型,但实际上它创建的系统缺乏可靠性并为特征漂移产生了高比表面,其中输入随时间变化。因此,在构建预测模型时,首先追求简单性和可靠性。这一策略还帮助DoorDash更快地创建了端到端的调动系统。
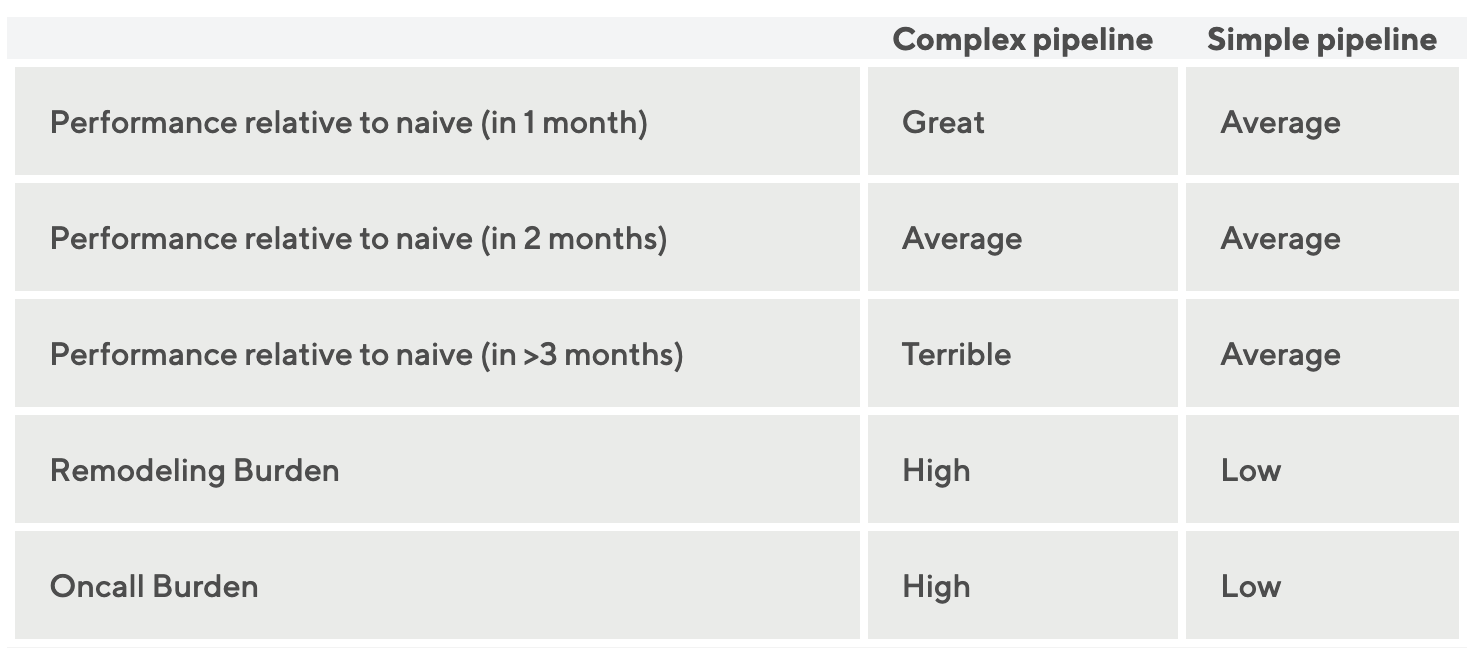
Figure 4: Models that have complex data pipelines generally can show their strength in the first weeks of deployment but rapidly deteriorate over time. Simple data pipelines are generally more robust and reduce maintenance and remodeling burden.
图4:具有复杂数据流程的模型通常可以在部署的最初几周显示其优势,但随着时间的推移会迅速恶化。简单的数据流程通常更健壮,并减少维护和改造负担。
To manage complexity and shifts in how data gets exposed, we did two things. First, we decoupled data pipelines from each other into separate business domains. Now, when someone is working on improving the signal for the inputs used in forecasting, they do not need to be overwhelmed by monolithic queries and data pipelines. Instead, a developer works on an isolated pipeline and only needs to ensure that aggregations are done on an appropriate entity.
为了管理数据暴露方式的复杂性和变化,DoorDash做了两件事。首先,将数据流程彼此解耦为单独的业务域。现在,当有人致力于改进用于预测的输入信息时,他们不需要被庞大的查询和数据流程所淹没。相反,开发人员在隔离的流程上工作,只需要确保在合适的实体上完成聚合。
The second thing we did was to remove intermediary data dependencies. We recognized that if our input signals come from ETL jobs with very long dependency chains in their directed acyclic graphs (DAGs), we would increase our surface areas for failures. Hence, we would aspire to rely on primary tables thoroughly vetted by our Business Intelligence team or a copy of production data sources for which the data generation is not hidden behind complex ETLs.
第二件事是移除中间数据依赖。DoorDash认识到,如果输入信息来自ETL任务,ETL任务在有向无环图(DAG)中具有非常长的依赖链,将增加失败的比表面。因此,DoorDash希望依赖由商业智能团队彻底审查过的主表或产品数据源的副本,其数据生成不会隐藏在复杂的ETL后面。

Figure 5: In this example, task E is the ML task with data transformations. If the source data for ML models comes from a long dependency chain in the ETL systems (A through D), there is a high risk of experiencing feature drift and data failures if any of the upstream dependencies fail.
图5:在此示例中,任务E是具有数据转换的ML任务。如果ML模型的源数据来自ETL系统中的长依赖链(A到D),那么如果任何上游依赖项失败,则存在发生特征漂移和数据故障的高风险。
Focus on experimentation
One of the best ways to test if our system is maintainable is to simply check on the iteration speed with which we can push new changes and launch experiments without creating bugs or introducing regressions. At DoorDash, we perform many experiments to determine whether a feature is working as intended. This generally means that we put a lot more emphasis on measuring the software quality by how quickly we can extend and deliver on new functionality. Unsurprisingly, if experiments are challenging to launch and new features are difficult to test, we have failed in our goal.
测试系统是否可维护的最好方法之一是简单地检查迭代速度,可以用它推动新的变化和启动实验,而不会产生错误或引入回退。在DoorDash,进行了许多实验来确定某个功能是否按预期工作。这通常意味着更加重视通过扩张和交付新功能的速度来衡量软件质量。不出所料,如果实验难以启动并且新功能难以测试,那么目标就失败了。
Similarly, if a system stays unchanged over a long period of time (e.g., six months or more), it would also be an indication that something is wrong, because it means we created a system that is rigid and does not invite improvements, ideation, and experimentation. Continuous experimentation is a forcing function towards adopting better practices, such as relying on a CI/CD system for automation, setting up library dependency management, decoupling the code into business domains, and adding testing, alerting, and documentation.
同样,如果一个系统在很长一段时间内(例如,六个月或更长时间)保持不变,这也表明出现了问题,因为这意味着创建了一个僵化的系统,不会引起改进、构思和实验。持续的实验是一个强制采用更好实践的功能,例如依靠CI/CD系统实现自动化,设置库依赖管理,将代码解耦到业务域,以及添加测试、警报和文档。
Results
Implementing this mobilization system let us more accurately allocate incentives to regional-time units that benefited most from the improved supply and demand balance. The system resulted in a better experience for our customers, as our metrics showed reductions in delivery times, cancelations, and extreme lateness. For Dashers, we were able to ensure that incentives are allocated in places where they are needed most. For merchants, we drove the overall order cancellations down. Moreover, due to improvements in forecasting accuracy, we were also able to more reliably hit budget expectations and observed less variability in spending decisions. Because of reliability improvements, we were able to get to a point where our experimentation velocity on the incentive mobilization system rapidly increased.
实现这种调动系统能够更准确地将激励分配给从改善的供需平衡中受益最多的区域时间单位。该系统为客户带来了更好的体验,因为指标显示交付时间、取消订单和极端延迟都减少了。对于Dasher,能够确保将激励措施分配到最需要的地方。对于商家而言,降低了整体订单取消率。此外,由于预测准确性的提高,还能够更可靠地达到预算预期,并观察到支出决策的变动更小。由于可靠性的提高,能够达到激励调用系统的实验速度迅速提高的地步。
Conclusion
Problems that deal with optimizing a system under constraints benefit immensely from aligning on metrics that estimate the impact of actions at an appropriate level of aggregation. If forecasts are done daily, but optimization actions are taken sub-daily, decision making will likely be suboptimal.
处理在约束条件下优化系统的问题极大地受益于在适当的聚合水平上调整估计行动影响的指标。如果每天进行预测,但次日采取优化措施,则决策可能次优的。
Secondly, we generally recommend decoupling forecasting components from decision-making components. Most optimization systems work better if the inputs have stable statistical properties where the forecast predictions are unbiased estimates. For example, it can be tempting to start using an asymmetric loss function in forecasting to align with whether we care more about underpredicting or overpredicting the output. Although this approach is perfect for a variety of problems where the output of an ML model is immediately used to drive the decision, for problems where the ML predictions are simply another input into a broader optimization engine, it is best to generate unbiased predictions. Instead, it is better to let an optimization engine handle tradeoffs.
其次,通常建议将预测组件与决策组件解耦。如果输入具有稳定的统计特性,其中预告预测是无偏估计,则大多数优化系统会工作地更好。例如,为了与更关心低估或高估输出保持一致,开始在预测中使用非对称损失函数可能是很诱人的。尽管这种方法非常适用于ML模型的输出立即用于驱动决策的各种问题,但对于ML预测只是更广泛优化引擎的另一个输入的问题,最好生成无偏预测。相反,最好让优化引擎处理权衡。

