文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
本文为美团文章学习的笔记整理。
1. 前言
在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(一般将商家标示为POI,POI基础信息包括:门店名称、品类、电话、地址、坐标等)。如何使用这些已校准的POI数据,挖掘出有价值的信息,本文进行了一些尝试:利用机器学习方法,自动标注缺失品类的POI数据。例如,门店名称为“好再来牛肉拉面馆”的POI将自动标注“小吃”品类。
Note:将商家标示为POI,POI基础信息包括:门店名称、品类、电话、地址、坐标等。
机器学习解决问题的一般过程:
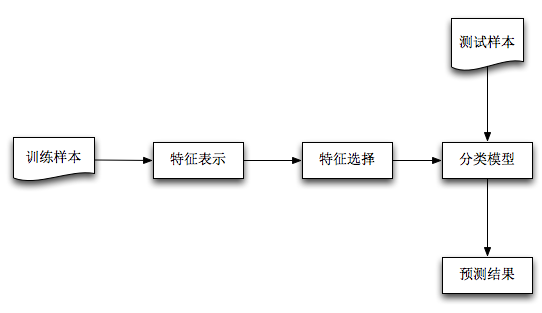
本文将按照:1)特征表示;2)特征选择;3)基于Naive Bayes分类模型;4)分类预测,四个部分顺序展开。
2. 特征表示
需要先将实际问题转换成计算机可识别的形式。对于POI而言,反应出POI品类的一个重要特征是POI门店名称,那么问题转换成了根据POI门店名称判别POI品类。POI名称字段属于文本特征,传统的文本表示方法是基于向量空间模型(VSM模型):
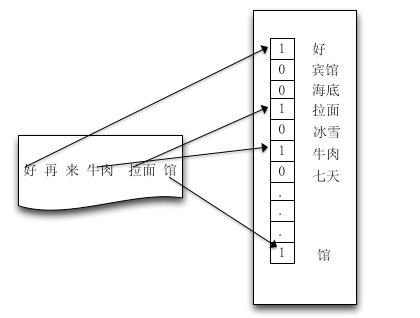
空间向量模型需要一个“字典”,这个字典可以在样本中产生,也可以从外部导入。上图中的字典就是[好,宾馆,海底,拉面,冰雪, ……. ,馆]。对已校准的POI,先利用Lucene的中文分词工具SmartCn[2]对POI名称做预分词处理,提取特征词,作为原始粗糙字典集合。
有了字典后便可以量化地表示出某个文本。先定义一个与字典长度相同的向量,向量中的每个位置对应字典中的相应位置的单词。然后遍历这个文本,对应文本中的出现某个单词,在向量中的对应位置,填入“某个值”(即特征词的权重,包括BOOL权重,词频权重,TFIDF权重)。考虑到一般的POI名称都属于短文本,本文采用BOOL权重。
在产生粗糙字典集合时,还统计了校准POI中,每个品类(type_id),以及特征词(term)在品类(type_id)出现的次数(文档频率)。分别写入到表category_frequency和term_category_frequency,表的部分结果如下:
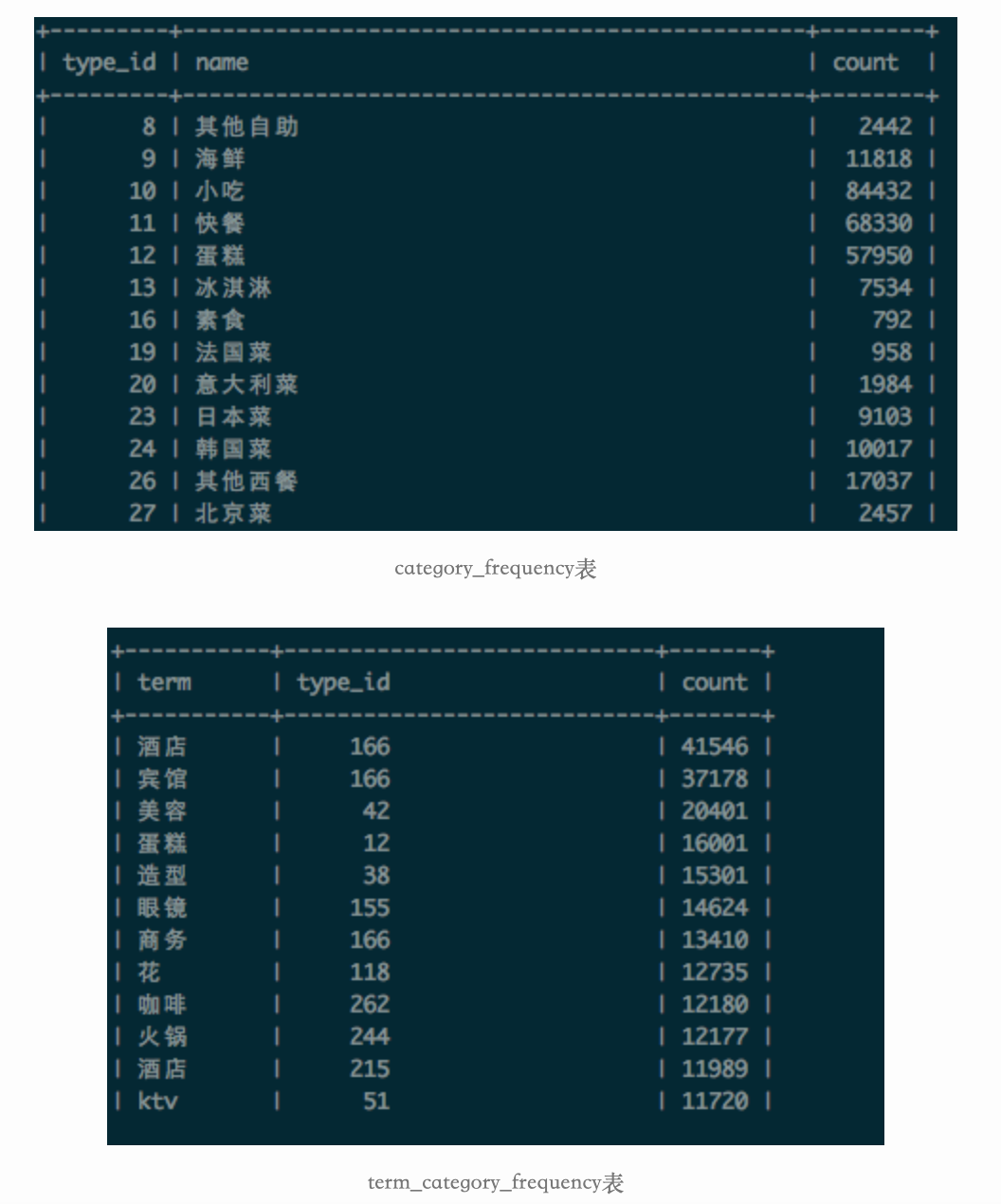
分别记:
1 | A(i,j) = 特征词term(i) 在品类为type_id(j)出现的次数count |
Note: 先分词,提取特征词,构造字典,然后使用VSM模型(Vector Space Model)表示文本,生成字典时可以统计词频。
3. 特征选择
现在,得到了一个“预输入字典”:包括了所有已校准POI名称字段的特征词,这些特征词比如:“88”、“11”, “3”、“auyi”、“中心”、“中国”、“酒店”、“自助餐”、“拉面”等。直观感觉,“88”、“11”, “3”、“auyi”、“中国”这些词对判断品类并没有多大帮助,但“酒店”、“自助餐”、“拉面”对判断一个POI的品类却可能起到非常重要作用。
如何挑选出有利于模型预测的特征呢?这就涉及到了特征选择。特征选择方法可以分成基于领域知识的规则方法和基于统计学习方法。本文使用统计机器学习方法,辅助规则方法的特征选择算法,挑选有利于判断POI品类的特征词。
3.1 基于统计学习的特征选择算法
基于统计学习的特征选择算法,大体可以分成两种:1.基于相关性度量(信息论相关) 2.特征空间表示(典型的如PCA)。
文本特征经常采用的基于信息增益方法(IG)特征选择方法。某个特征的信息增益是指,已知该特征条件下,整个系统的信息量的前后变化。如果前后信息量变化越大,那么可以认为该特征起到的作用也就越大。 那么,如何定义信息量呢?一般采用熵的概念来衡量一个系统的信息量:$$H(Y)=-\sum_{i=1}^{n}p(y_{i})\log p(y_{i})$$
当已知该特征时,从数学的角度来说就是已知了该特征的分布,系统的信息量可以由条件熵来描述:$$H(Y|X)=\sum_{x} p(x)H(Y|X=x)=- \sum_{x} \sum_{y} p(x,y)\log p(y|x)$$
该特征的信息增益定义为:$$IG(X)=H(Y)-H(Y|X)$$
信息增益得分衡量了该特征的重要性。假设有四个样本,样本的特征词包括“火锅”、“米粉”、“馆”,采用信息增益判断不同特征对于决策影响:
| 米粉(A) | 火锅(B) | 馆(C) | 品类(D) |
| 1 | 1 | 0 | 火锅 |
| 0 | 1 | 1 | 火锅 |
| 1 | 0 | 0 | 小吃 |
| 1 | 0 | 1 | 小吃 |
整个系统的最原始信息熵为:
$$H(Y)=-\sum_{i=1}^{2} p(y_{i}) \log p(y_{i})=-2 * \frac {1} {2} * \log \frac {1} {2} = 1$$
分别计算每个特征的条件熵:
$$H(D|A)=- \sum_{i=1}^{2}\sum_{j=1}^{2}p(x,y)\log p(y|x)=0 - 0 - \frac {1} {2} \log \frac {2} {3} - \frac {1} {4} \log \frac {1} {3} =0.69$$
利用整个系统的信息熵减去条件熵,得到每个特征的信息增益得分排名(“火锅”(1) > “米粉”(0.31) > “馆”(0)) ,按照得分由高到低挑选需要的特征词。
本文采用IG特征选择方法,选择得分排名靠前的N个特征词(Top 30%)。抽取排名前20的特征词:[酒店, 宾馆, 火锅, 摄影, 眼镜, 美容, 咖啡, ktv, 造型, 汽车, 餐厅, 蛋糕, 儿童, 美发, 商务, 旅行社, 婚纱, 会所, 影城, 烤肉]。这些特征词明显与品类属性相关联具有较强相关性,将其称之为品类词。
3.2 基于领域知识的特征选择方法
基于规则的特征选择算法,利用领域知识选择特征。目前很少单独使用基于规则的特征选择算法,往往结合统计学习的特征选择算法,辅助挑选特征。
本文需要解决的是POI名称字段短文本的自动分类问题,POI名称字段一般符合这样的规则,POI名称=名称核心词+品类词。名称核心词对于实际的品类预测作用不大,有时反而出现”过度学习“起到负面作用。例如”好利来牛肉拉面馆“,”好利来“是它的名称核心词,在用学习算法时学到的很有可能是一个”蛋糕“品类(”好利来“和”蛋糕“品类的关联性非常强,得到错误的预测结论)。
本文使用该规则在挑选特征时做了一个trick:利用特征选择得到的特征词(绝大部分是品类词),对POI名称字段分词,丢弃前面部分(主要是名称核心词),保留剩余部分。这种trick从目前的评测结果看有5%左右准确率提升,缺点是会降低了算法覆盖度。
Note: 利用领域知识集合统计学习来选择特征。
4. 分类模型
4.1 建模
完成了特征表示、特征选择后,下一步就是训练分类模型了。机器学习分类模型可以分成两种:1)生成式模型;2)判别式模型。可以简单认为,两者区别生成式模型直接对样本的联合概率分布进行建模:生成式模型的难点在于如何去估计类概率密度分布$p(x|y)$。本文采用的朴素贝叶斯模型,其”Naive”在对类概率密度函数简化上,它假设了条件独立:$$p(y|x)=\frac {p(y)p(x|y)} {p(x)} \sim p(x|y)$$
根据对p(x|y)不同建模形式,Naive Bayes模型主要分成:Muti-variate Bernoulli Model(多项伯努利模型)和Multinomial event model(多项事件模型)。一次伯努利事件相当于一次投硬币事件(0,1两种可能),一次多项事件则相当于投色子(1到6多种可能)。结合传统的文本分类解释这两类模型。
4.1.1 多项伯努利模型
已知类别的条件下,多项伯努利对应样本生X成过程:遍历字典中的每个单词$(t_{1},t_{2},…,t_{|V|})$,判断这个词是否在样本中出现。每次遍历都是一次伯努利实验,$|V|$次遍历:

